- 发布日期:2023-10-24 06:19 点击次数:184

群众好开云炸金花,我是林哥!
HDFS全称是 Hadoop Distribute File System,是 Hadoop最蹙迫的组件之一,也被称为分步式存储之王。本文主要从 HDFS 高可用架构组成、HDFS 读写进程、如何保证可用性以及高频口试题启程,提升群众对 HDFS 的意识,掌捏一些高频的 HDFS 口试题。本篇著作概览如下图:
本篇著作概览
1.HA 架构组成 1.1HA架构模子在 HDFS 1.X 时,NameNode 是 HDFS 集群中可能发生单点故障的节点,集群中只须一个 NameNode,一朝 NameNode 宕机,通盘这个词集群将处于不能用的景况。
太阳城娱乐网站在 HDFS 2.X 时,HDFS 提议了高可用(High Availability, HA)的有操办,治理了 HDFS 1.X 时的单点问题。在一个 HA 集群中,会建立两个 NameNode ,一个是 Active NameNode(主),一个是 Stadby NameNode(备)。主节点讲求实施通盘修改定名空间的操作,备节点则实施同步操作,以保证与主节点定名空间的一致性。HA 架构模子如下图所示:
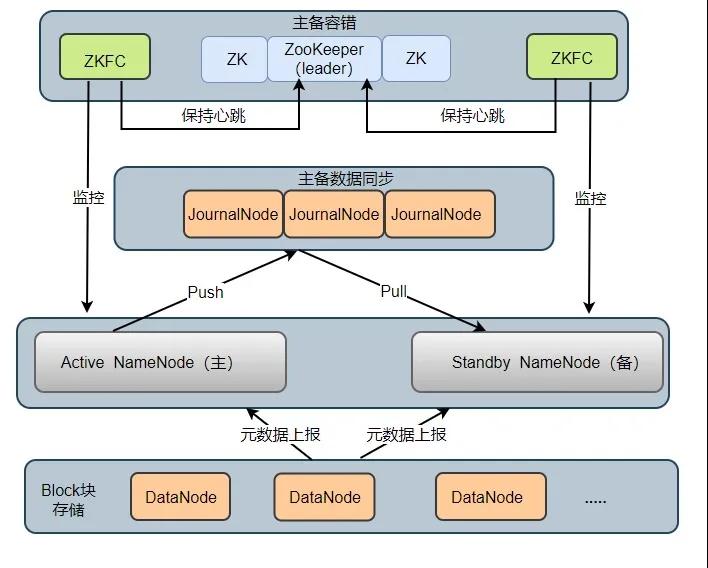
HA 架构组成2
HA 集群中所包含的程度的服务各不调换。为了使得主节点和备用节点的景况一致,聘用了 Quorum Journal Manger (QJM)有操办治理了主备节点分享存储问题,如图 JournalNode 程度,底下瓜代先容各个程度在架构中所起的作用:
Active NameNode:它讲求实施通盘这个词文献系统中定名空间的通盘操作;珍视着数据的元数据,包括文献名、副本数、文献的 BlockId 以及 Block 块所对应的节点信息;另外还承袭 Client 端读写请乞降 DataNode 呈报 Block 信息。 Standby NameNode:它是 Active NameNode 的备用节点,一朝主节点宕机,备用节点会切换成主节点对外提供服务。它主若是监听 JournalNode Cluster 上 editlog 变化,以保证现时定名空间尽可能的与主节点同步。轻易时候,HA 集群只须一台 Active NameNode,另一个节点为 Standby NameNode。 JournalNode Cluster: 用于主备节点间分享 editlog 日记文献的分享存储系统。讲求存储 editlog 日记文献, 当 Active NameNode 实施了修改定名空间的操作时,它会如期将实施的操作记载在 editlog 中,并写入 JournalNode Cluster 中。Standby NameNode 会一直监听 JournalNode Cluster 上 editlog 的变化,如果发现 editlog 有更动,备用节点会读取 JournalNode 上的 editlog 并与我方现时的定名空间合并,从良友毕了主备节点的数据一致性。能干:QJM 有操办是基于 Paxos 算法已毕的,集群由 2N + 1 JouranlNode 程度组成,最多不错容忍 N 台 JournalNode 宕机,宕机数大于 N 台,这个算法就失效了!
ZKFailoverController: ZKFC 以平安程度运行,每个 ZKFC 皆监控我方讲求的 NameNode,它不错已毕 NameNode 自动故障切换:即当主节点相称,监控主节点的 ZKFC 则会断开与 ZooKeeper 的估计,开释分步式锁,监控备用节点的 ZKFC 程度会去获取锁,同期把备用 NameNode 切换成 主 NameNode。 ZooKeeper: 为 ZKFC 程度已毕自动故障滚动提供长入协作服务。通过 ZooKeeper 中 Watcher 监听机制,告知 ZKFC 相称NameNode 下线;保证兼并时候只须一个主节点。 DataNode: DataNode 是实质存储文献 Block 块的方位,一个 Block 块包含两个文献:一个是数据本人,一个是元数据(数据块长度、块数据的校验和、以实时候戳),DataNode 启动后会向 NameNode 注册,每 6 小时同期向主备两个 NameNode 上报通盘的块信息,每 3 秒同期向主备两个 NameNode 发送一次心跳。DataNode 向 NameNode 呈报现时块信息的时候休止,默许 6 小时,其建立参数名如下:
<property> <name>dfs.blockreport.intervalMsec</name> <value>21600000</value> <description>Determines block reporting interval in milliseconds.</description> </property>
1.2HA主备故障切换进程
HA 集群刚启动时,两个 NameNode 节点景况均为 Standby,之后两个 NameNode 节点启动 ZKFC 程度后会去 ZooKeeper 集群霸占分步式锁,见效获取分步式锁,ZooKeeper 会创建一个临时节点,见效霸占分步式锁的 NameNode 会成为 Active NameNode,ZKFC 便会实时监控我方的 NameNode。
HDFS 提供了两种 HA 景况切换样式:一种是照管员手动通过DFSHAAdmin -faieover实施景况切换;另一种则是自动切换。底下分别从两种情况分析故障的切换进程:
1.主 NameNdoe 宕机后,备用 NameNode 如何升级为主节点?
当主 NameNode 宕机后,对应的 ZKFC 程度检测到 NameNode 景况,便向 ZooKeeper 发生删除锁的号令,锁删除后,则触发一个事件回调备用 NameNode 上的 ZKFC
ZKFC 得到音书后先去 ZooKeeper 争夺创建锁,锁创建完成后会检测原先的主 NameNode 是否确凿挂掉(有可能由于累积延伸,心跳延伸),挂掉则升级备用 NameNode 为主节点,没挂掉则将原先的主节点左迁为备用节点,将我方对应的 NameNode 升级为主节点。
2.主 NameNode 上的 ZKFC 程度挂掉,主 NameNode 没挂,如何切换?
ZKFC 挂掉后,ZKFC 和 ZooKeeper 之间 TCP 衔接会随之断开,session 也会随之消散,锁被删除,触发一个事件回调备用 NameNode ZKFC,ZKFC 得到音书后会先去 ZooKeeper 争夺创建锁,锁创建完成后也会检测原先的主 NameNode 是否确凿挂掉,挂掉则升级 备用 NameNode 为主节点,没挂掉则将主节点左迁为备用节点,将我方对应的 NameNode 升级为主节点。
1.3Block、packet及chunk 观念在 HDFS 中,文献存储是按照数据块(Block)为单元进行存储的,在读写数据时,DFSOutputStream使用 Packet 类来封装一个数据包。每个 Packet 包含了几许个 chunk 和对应的 checksum。
Block: HDFS 上的文献皆是分块存储的,即把一个文献物理别离为一个 Block 块存储。Hadoop 2.X/3.X 默许块大小为 128 M,1.X 为 64M. Packet: 是 Client 端向 DataNode 或 DataNode 的 Pipline 之间传输数据的基本单元,默许 64 KB Chunk: Chunk 是最小的单元,它是 Client 向 DataNode 或 DataNode PipLine 之间进行数据校验的基本单元,默许 512 Byte ,因为用作校验,是以每个 Chunk 需要带有 4 Byte 的校验位,实质上每个 Chunk 写入 Packtet 的大小为 516 Byte。 2.源码级读写进程 2.1HDFS 读进程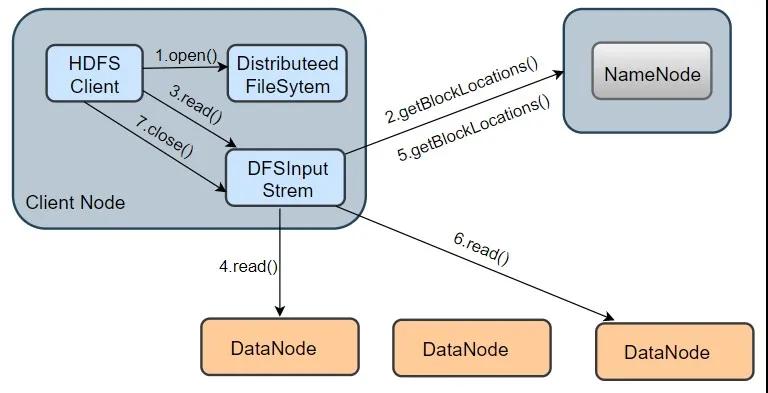
HDFS读进程
皇冠客服飞机:@seo3687咱们以从 HDFS 读取一个 information.txt 文献为例,其读取进程如上图所示,分为以下几个要领:
1.翻开 information.txt 文献:最初客户端调用 DistributedFileSystem.open() 口头翻开文献,这个口头在底层会调用DFSclient.open() 口头,该口头会复返一个 HdfsDataInputStream 对象用于读取数据块。但实质上简直读取数据的是 DFSInputStream ,而 HdfsDataInputStream 是 DFSInputStream 的遮蔽类(new HdfsDataInputStream(DFSInputStream))。
2.从 NameNode 获取存储 information.txt 文献数据块的 DataNode 地址:即获取组成 information.txt block 块信息。在构造输出流 DFSInputStream 时,通晓过调用 getBlockLocations() 口头向 NameNode 节点获取组成 information.txt 的 block 的位置信息,何况 block 的位置信息是按照与客户端的距离遐迩排好序。
3.估计 DataNode 读取数据块: 客户端通过调用 DFSInputStream.read() 口头,估计到离客户端最近的一个 DataNode 读取 Block 块,数据会以数据包(packet)为单元从 DataNode 通过流式接口授到客户端,直到一个数据块读取完成;DFSInputStream会再次调用 getBlockLocations() 口头,获取下一个最优节点上的数据块位置。
皇冠体育博彩网站不仅提供最优秀的博彩服务,还有专业的博彩攻略和技巧分享,帮助广大博彩爱好者更好的了解博彩知识和赢取更高额的奖金。4.直到通盘文献读取完成,调用 close() 口头,关闭输入流,开释资源。
从上述进程可知,通盘这个词过程最主要波及到 open()、read()两个口头(其它口头皆是在这两个口头的调用链中调用,如getBlockLocations()),底下瓜代先容这2个口头的已毕。
赛场激情皇冠网址大全注:本文是以 hadoop-3.1.3 源码为基础!
open()口头事实上,在调用 DistributedFileSystem.open()口头时,底层调用的是 DFSClient.open()口头翻开文献,并构造 DFSInputStream 输入流对象。
皇冠完整比分网public DFSInputStream open(String src, int buffersize, boolean verifyChecksum) throws IOException { //查验DFSClicent 的运事业况 checkOpen(); // 从 namenode 获取 block 位置信息,并存到 LocatedBlocks 对象中,最终传给 DFSInputStream 的构造口头 try (TraceScope ignored = newPathTraceScope("newDFSInputStream", src)) { LocatedBlocks locatedBlocks = getLocatedBlocks(src, 0); //调用 openInternal 口头,获取输入流 return openInternal(locatedBlocks, src, verifyChecksum); } }
通盘这个词 open()口头分为两部分:
第一部分是,调用 checkOpen()口头查验 DFSClient 的运事业况,调用getLocateBlocks()口头,获取 block 的位置音书
亚星炸金花第二部分是,调用openInternal()口头,欧博体育入口获取输入流。
openInternal( )口头private DFSInputStream openInternal(LocatedBlocks locatedBlocks, String src, boolean verifyChecksum) throws IOException { if (locatedBlocks != null) { //获取纠删码战略,纠删码是 Hadoop 3.x 的新特质,默许不启用纠删码战略 ErasureCodingPolicy ecPolicy = locatedBlocks.getErasureCodingPolicy(); if (ecPolicy != null) { //如果用户指定了纠删码战略,将复返一个 DFSStripedInputStream 对象 //DFSStripedInputStream 会将数据逻辑字节规模的请求调度为存储在 DataNode 上的里面块 return new DFSStripedInputStream(this, src, verifyChecksum, ecPolicy, locatedBlocks); } //如果未指定纠删码战略,调用 DFSInputStream 的构造口头,何况复返该 DFSInputStream 的对象 return new DFSInputStream(this, src, verifyChecksum, locatedBlocks); } else { throw new IOException("Cannot open filename " + src); } }
DFSInputStream 构造口头
DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum, LocatedBlocks locatedBlocks) throws IOException { this.dfsClient = dfsClient; this.verifyChecksum = verifyChecksum; this.src = src; synchronized (infoLock) { this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy(); } this.locatedBlocks = locatedBlocks; //调用 openInfo 口头,参数:refreshLocatedBlocks,是否要更新 locateBlocks 属性。 openInfo(false); }
构造口头作念了2件事:
第一部分是开动化 DFSInputStream 属性,其中 verifyChecksum 含义是:读取数据时是否进行校验,cachingStrategy,指的是缓存战略。
皇冠博彩下载第二部分,调用 openInfo()口头。
念念考:为甚么要更新终末一个数据块长度?
因为可能会有这种情况出现,当客户端在读取文献时,终末一个文献块可能还在构建的景况(正在被写入),Datanode 还未上报终末一个文献块,那么 namenode 所保存的数据块长度有可能小于 Datanode实质存储的数据块长度,是以需要与 Datanode 通讯以阐明终末一个数据块的真实长度。
获取到 DFSInputStream 流对象后,何况得到了文献的通盘 Block 块的位置信息,接下来调用read()口头,从 DataNode 读取数据块。
注:在openInfo() 口头

在openInfp()中,会从 namenode 获取现时正在读取文献的终末一个数据块的长度 lastBlockBeingWrittenLength,如果复返的终末一个数据块的长度为 -1 ,这是一种迥殊情况:即集群刚重启,DataNode 可能还莫得向 NN 进行齐全的数据块呈报,这时部分数据块位置信息还获取不到,也获取不到这些块的长度,则默许会重试 3 次,默许每次恭候 4 秒,重新去获取文献对应的数据块的位置信息以及终末数据块长度;如果终末一个数据块的长度不为 -1,则标明,终末一个数据块依然是齐全景况。
read()口头public synchronized int read(@Nonnull final byte buf[], int off, int len) throws IOException { //考证输入的参数是否可用 validatePositionedReadArgs(pos, buf, off, len); if (len == 0) { return 0; } //构造字节数组动作容器 ReaderStrategy byteArrayReader = new ByteArrayStrategy(buf, off, len, readStatistics, dfsClient); //调用 readWithStrategy()口头读取数据 return readWithStrategy(byteArrayReader); }
当用户代码调用read()口头时,其底层调用的是 DFSInputStream.read()口头。该口头从输入流的 off 位置入手读取,读取 len 个字节,然后存入 buf 字节数组中。源码中构造了一个 ByteArrayStrategy 对象,该对象封装了 5 个属性,分别是:字节数组 buf,读取到的字节存入该字节数组;off,读取的偏移量;len,将要读取的讨论长度;readStatistics,统计计数器,客户端。终末通过调用 readWithStrategy()口头去读取文献数据块的数据。
回顾:HDFS 读取一个文献,调用进程如下:(中间波及到的部分口头未列出)
usercode 调用 open() ---> DistributedFileSystem.open() ---> DFSClient.open() ---> 复返一个 DFSInputStream 对象给 DistributedFileSystem ---> new hdfsDataInputStream(DFSInputStream) 并复返给用户;
usercode 调用 read() ---> 底层DFSIputStream.read() ---> readWithStrategy(bytArrayReader)
2.2HDFS 写进程先容完 HDFS 读的进程,接下来望望一个文献的写操作的已毕。从下图中不错看出,HDFS 写进程波及的口头相比多,过程也相比复杂。
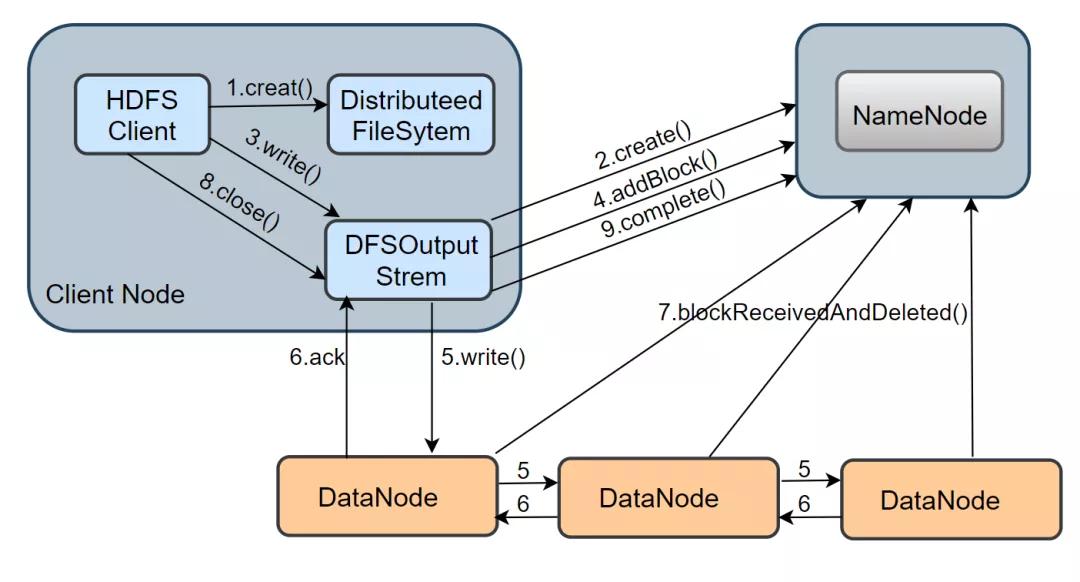
1.在 namenode 创建文献: 当 client 写一个新文献时,最初会调用 DistributeedFileSytem.creat() 口头,DistributeFileSystem 是客户端创建的一个对象,在收到 creat 号令之后,DistributeFileSystem 通过 RPC 与 NameNode 通讯,让它在文献系统的 namespace 创建一个平安的新文献;namenode 会先阐明文献是否存在以及客户端是否有权限,阐明见效后,会复返一个 HdfsDataOutputStream 对象,与读进程近似,这个对象底层包装了一个 DFSOutputStream 对象,它才是写数据的简直实施者。
2.建设数据流 pipeline 管说念: 客户端得到一个输出流对象,还需要通过调用 ClientProtocol.addBlock()向 namenode 请求新的空数据块,addBlock( ) 会复返一个 LocateBlock 对象,该对象保存了可写入的 DataNode 的信息,并组成一个 pipeline,默许是有三个 DataNode 组成。
3.通过数据流管说念写数据: 当 DFSOutputStream调用 write()口头把数据写入时,数据会先被缓存在一个缓冲区中,写入的数据会被切分红多个数据包,每当达到一个数据包长度(默许65536字节)时,
DFSOutputStream会构造一个 Packet 对象保存这个要发送的数据包;新构造的 Packet 对象会被放到 DFSOutputStream珍视的 dataQueue 部队中,DataStreamer 线程会从 dataQueue 部队中取出 Packet 对象,通过底层 IO 流发送到 pipeline 中的第一个 DataNode,然后不绝将通盘的包转到第二个 DataNode 中,依此类推。发送完了后,
这个 Packet 会被移出 dataQueue,放入 DFSOutputStream 珍视的阐明部队 ackQueue 中,该部队恭候卑劣 DataNode 的写入阐明。当一个包依然被 pipeline 中通盘的 DataNode 阐明了写入磁盘见效,这个数据包才会从阐明部队中移除。
4.关闭输入流并提交文献: 当客户端完成了通盘这个词文献中通盘的数据块的写操作之后,会调用 close() 口头关闭输出流,客户端还会调用 ClientProtoclo.complete( ) 口头告知 NameNode 提交这个文献中的所稀有据块,
NameNode 还会阐明该文献的备份数是否知足条目。关于 DataNode 而言,它会调用 blockReceivedAndDelete() 口头向 NameNode 呈报,NameNode 会更新内存中的数据块与数据节点的对应关连。
从上述进程来看,通盘这个词写进程主要波及到了 creat()、write()这些口头,底下注重先容下这两个口头的已毕。当调用 DistributeedFileSytem.creat() 口头时,其底层调用的其实是 DFSClient.create()口头,其源码如下:
博彩平台游戏论坛 create( )口头public DFSOutputStream create(String src, FsPermission permission, EnumSet<CreateFlag> flag, boolean createParent, short replication,long blockSize, Progressable progress, int buffersize, ChecksumOpt checksumOpt, InetSocketAddress[] favoredNodes, String ecPolicyName) throws IOException { //查验客户端是否依然翻开 checkOpen(); final FsPermission masked = applyUMask(permission); LOG.debug("{}: masked={}", src, masked); //调用 DFSOutputStream.newStreamForCreate()创建输出流对象 final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this, src, masked, flag, createParent, replication, blockSize, progress, dfsClientConf.createChecksum(checksumOpt), getFavoredNodesStr(favoredNodes), ecPolicyName); //获取 HDFS 文献的租约 beginFileLease(result.getFileId(), result); return result; }
DistributeFileSystem.create()在底层会调用 DFSClient.create()口头。该口头主要完成三件事:
租约:指的是租约持有者在口头时候内赢得该文献权限(写文献权限)的条约
第一,查验客户端是否依然翻开
第二,调用静态的 newStreamForCreate() 口头,通过 RPC 与 NameNode 通讯创建新文献,并构建出 DFSOutputStream流
第三,实施 beginFileLease() 口头,获取新J建文献的租约
皇冠体育hg86a
newStreamForCreate() 口头static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src, FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent, short replication, long blockSize, Progressable progress, DataChecksum checksum, String[] favoredNodes, String ecPolicyName) throws IOException { try (TraceScope ignored = dfsClient.newPathTraceScope("newStreamForCreate", src)) { HdfsFileStatus stat = null; // 如果发生相称,何况相称为 RetryStartFileException ,便重新调用create()口头,重试次数为 10 boolean shouldRetry = true; //重试次数为 10 int retryCount = CREATE_RETRY_COUNT; while (shouldRetry) { shouldRetry = false; try { //调用 ClientProtocol.create() 口头,在定名空间中创建 HDFS 文献 stat = dfsClient.namenode.create(src, masked, dfsClient.clientName, new EnumSetWritable<>(flag), createParent, replication, blockSize, SUPPORTED_CRYPTO_VERSIONS, ecPolicyName); break; } catch (RemoteException re) { IOException e = re.unwrapRemoteException(AccessControlException.class, //....此处不详了部分相称类型 UnknownCryptoProtocolVersionException.class); if (e instanceof RetryStartFileException) {//如果发生相称,判断相称是否为 RetryStartFileException if (retryCount > 0) { shouldRetry = true; retryCount--; } else { throw new IOException("Too many retries because of encryption" + " zone operations", e); } } else { throw e; } } } Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!"); final DFSOutputStream out; if(stat.getErasureCodingPolicy() != null) { //如果用户指定了纠删码战略,将创建一个 DFSStripedOutputStream 对象 out = new DFSStripedOutputStream(dfsClient, src, stat, flag, progress, checksum, favoredNodes); } else { //如果没指定纠删码战略,调用构造口头创建一个 DFSOutputStream 对象 out = new DFSOutputStream(dfsClient, src, stat, flag, progress, checksum, favoredNodes, true); } //启动输出流对象的 Datastreamer 线程 out.start(); return out; } }
newStreamForCreate()口头统统波及三个部分:
当构建完 DFSOutputStream 输出流时,客户端调用 write() 口头把数据包写入 dataQueue 部队,在将数据包发送到 DataNode 之前,DataStreamer会向 NameNode 请求分派一个新的数据块
然后建设写这个数据块的数据流管说念(pipeline),之后DataStreamer 会从 dataQueue 部队取出数据包,通过 pipeline 瓜代发送给各个 DataNode。每个数据包(packet)皆有对应的序列号,当一个数据块中通盘的数据包皆发送完了,
何况皆得到了 ack 音书阐明后,Datastreamer会将现时数据块的 pipeline 关闭。通过不停轮回上述过程,直到该文献(一个文献会被切分为多个 Block)的所稀有据块皆写完成。
调用 ClientProtocol.create()口头,创建文献,如果发生相称为 RetryStartFileException ,则默许重试10次
调用 DFSStripedOutputStream 或 DFSOutputStream 构造口头,构造输出流对象
启动 Datastreamer 线程,Datastreamer 是 DFSOutputStream 中的一个里面类,讲求构建 pipeline 管说念,并将数据包发送到 pipeline 中的第一个 DataNode
从国内物流到国际物流,从公路运输到铁路运输,济南土生土长的山东盖世国际物流集团正加速转型升级,以崭新的姿态服务国内国际“双循环”,而这也是近些年来济南以高质量发展推动打造全国重要的区域性物流中心的一个缩影。
“三好”济南开云炸金花,才是这座1.2万亿体量的城市应该有的样子!
writeChunk()口头protected synchronized void writeChunk(ByteBuffer buffer, int len, byte[] checksum, int ckoff, int cklen) throws IOException { writeChunkPrepare(len, ckoff, cklen); //将现时校验数据、校验块写入数据包中 currentPacket.writeChecksum(checksum, ckoff, cklen); currentPacket.writeData(buffer, len); currentPacket.incNumChunks(); getStreamer().incBytesCurBlock(len); // 如果现时数据包依然满了,有时写满了一个数据块,则将现时数据包放入发送部队中 if (currentPacket.getNumChunks() == currentPacket.getMaxChunks()